
Paged Attention and vLLM
Published:
Paged Attention is a memory optimization on which the vLLM Inference Engine is based. Here is a summary of the paper on paged attention and the key features of vLLM that make it so powerful.
Introduction
Paged attention is an innovative approach inspired by the concepts of virtual memory and page tables in operating systems. vLLM builds on this idea to efficiently manage memory during inference. The true magic of paged attention lies in how it stores the KV cache in memory, ensuring optimal memory usage and high performance.
Large language models (LLMs) operate in two phases: prefill and decoding. In the prefill phase, the model computes key (K) and value (V) vectors and caches them for later use during the decoding phase. This cached data, known as the KV cache, plays a crucial role in generating responses.
What Is the KV Cache?
The KV cache is essential for efficient LLM inference. Here’s how it works:
Prefill Phase:
When a request is received, the model processes the input tokens and computes the corresponding key and value vectors. These vectors are stored sequentially in the cache.Decoding Phase:
During response generation, the model reuses the stored KV vectors to predict subsequent tokens without recomputing them.
Structure of the KV Cache
For each request, the KV cache holds:
- Key and Value vectors: Two sets per token.
- Dimensions: Each vector is of size hidden dimension.
- Sequence: Vectors for each token in the sequence.
- Layers: The KV cache spans all layers of the model.
For instance, consider the 13B OPT model:
- Vectors: 2 (one for keys and one for values)
- Hidden state dimensions: 5120
- Layers: 40
- Memory per element: 2 bytes (using FP16)
This results in roughly 800 KB of memory per token. With a maximum sequence length of 2048 tokens, a single request could require up to 1.6 GB of memory for the KV cache.
Memory Challenges in LLM Inference
Inference for LLMs is often memory bound. While GPUs such as the H100 deliver twice the FLOPs of the A100, they share similar high-bandwidth memory (HBM) capacities—typically around 80 GB. This makes memory and memory bandwidth significant bottlenecks in serving multiple requests.
The Problem with Contiguous Memory Allocation
Earlier designs allocated a contiguous block of memory for each request based on the model’s maximum response length. For example, if a model has a maximum sequence length of 2048 tokens, that full length is reserved for every request—even if the actual response is shorter.
Consider a model that, on average, generates 1000 tokens per request. In such cases, approximately 1048 tokens worth of memory remain unused. This unused memory cannot be reallocated for other requests, leading to severe fragmentation. In practice, research indicates that only 20-40% of the allocated memory is used for tokens, with the rest wasted due to fragmentation.
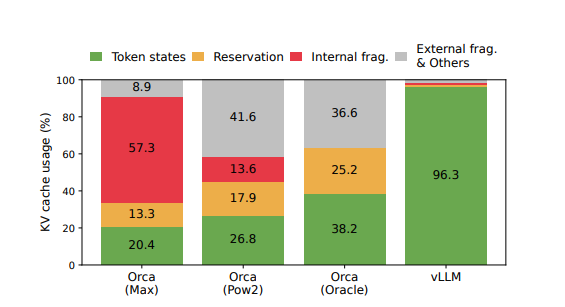
The Concept of Paged Attention
Paged attention addresses the memory fragmentation issue by rethinking how memory is allocated for the KV cache. Instead of reserving one large contiguous block per request, the memory is divided into logical blocks. Each logical block is designed to store the key and value vectors for a predefined number of tokens.
How It Works
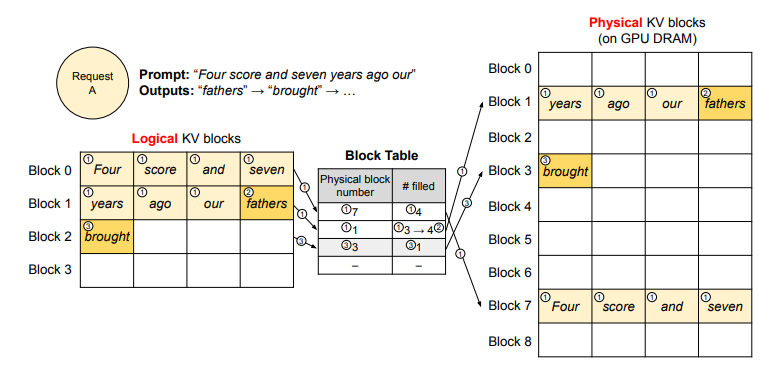
Logical Blocks:
Each logical block (similar to a virtual address) can store a fixed number of tokens’ KV vectors. When a block is full, a new block is allocated.Block Table Mapping:
These logical blocks are mapped to physical blocks on the GPU’s DRAM through a block table, which functions similarly to a page table in operating systems.During the Prefill Phase:
The first forward pass stores the KV vectors for the input tokens in a logical block (e.g., Block 0). Once this block is exhausted, a new block (e.g., Block 1) is allocated.During the Decoding Phase:
As new tokens are generated, their corresponding KV vectors are stored in the same logical block as the last chunk of the input prompt. If the current block fills up, another block (e.g., Block 2) is created.
This strategy ensures that each request only reserves memory for the actual tokens generated rather than for the entire potential sequence length.
Analogy with Operating Systems
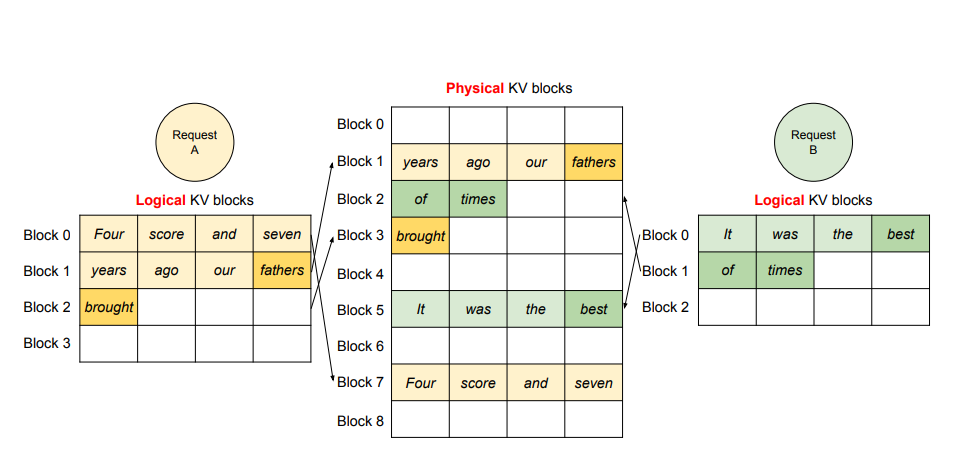
The design of paged attention closely mirrors the memory management in operating systems. In traditional systems, a process is given virtual pages, each mapped to physical memory frames through a page table. Although the process sees a contiguous block of memory, it is physically scattered across different areas of RAM.
Similarly, in vLLM:
- Each request is allocated logical blocks on demand.
- These blocks are mapped to non-contiguous physical memory on the GPU.
- This approach minimizes wastage, as memory is reserved only for the actual positions that will be used.
Batching Techniques in Inference
Efficient batching is another key aspect of large language model inference. Two main challenges arise:
Asynchronous Request Arrival:
Requests may arrive at different times. A naive solution would be to delay processing until multiple requests are ready, or to wait until the current batch is complete.Varying Lengths of Input and Output:
When requests have different sequence lengths, using padding tokens to equalize their lengths can lead to inefficient computations.
A Better Approach
A more effective method is to operate at the iteration level:
- After each iteration, completed requests are removed from the batch.
- New requests are added dynamically.
- This method ensures that the GPU processes only actual data rather than dummy tokens from padding.
- As a result, an incoming request only waits for the current iteration to finish, thereby enhancing overall efficiency.
Conclusion
Efficient memory management is crucial for large language model inference. By leveraging the concept of paged attention, vLLM significantly reduces memory fragmentation and optimizes GPU memory usage. This innovative design, inspired by operating system principles, not only makes better use of available resources but also improves the performance and scalability of LLM inference.